
It’s important that any website, regardless of scale, is set up to be technically excellent. For large websites, this is imperative to achieve desired increases in page indexing and resulting organic visibility.
What qualifies as a “large website” will undoubtedly vary based on personal opinion, but for the purpose of this post, I’m talking about websites with literally hundreds of thousands, if not millions of unique URLs.
Why large websites present a challenge for SEO
Large-scale websites present challenges for both webmasters and SEOs for a number of reasons;
First of all, the scale of these sites means that the existence of fundamental technical errors are likely to multiply many times over, increasing the total number of issues a search engine crawler will detect. These issues, over time, may potentially downgrade the overall quality of the site and lead to indexing and visibility issues.
Secondly, huge websites can present challenges for search engine crawlers as they look to understand the site structure, which pages to crawl and for how long to spend crawling the site.
Crawl Budget
The concept briefly described above is widely referred to as crawl budget, which in itself has received various definitions in recent years and Google has also stated that they “don’t have a single term that would describe everything that “crawl budget” stands for.
At the end of 2016, however, Gary Illyes from Google wrote this post, to provide clarity on in relation to crawl budget. In summary, he said;
“Prioritizing what to crawl, when, and how many resources the server hosting the site can allocate to crawling is more important for bigger sites or those that auto-generate pages based on URL parameters,”
“Crawl rate limit is designed to help Google not crawl your pages too much and too fast where it hurts your server.”
“Crawl demand is how much Google wants to crawl your pages. This is based on how popular your pages are and how stale the content is in the Google index.”
Crawl budget is “taking crawl rate and crawl demand together.” Google defines crawl budget as “the number of URLs Googlebot can and wants to crawl.”
With large websites, we need to give the search engines crawler the best experience possible, reduce confusion around which pages to crawl, and ultimately make the whole crawling process as efficient as possible.
Identifying technical SEO issues with large websites
In order to identify and analyse the issues, you’ll need access to a few things, the first one being Google Search Console. There are various sections within GSC which will become your best friend when analysing technical SEO performance, namely the index and crawl areas of the interface.
In addition, I’d highly recommend using an enterprise web crawler which you can set to crawl your website and as result then analyse your site’s architecture and understand and monitor technical issues, to improve your SEO performance.
Here at Impression, our tool of choice is DeepCrawl.
Finally, although there’s no substitute for experience, it’s vital to continuously refer to Google’s own Webmaster Guidelines to ensure and sense check any proposed fixes.
Common technical SEO issues with large websites
With all of the above in mind, I’d like to share some of the common errors, based on experience, which I’ve encountered when auditing and addressing technical SEO issues on large websites.
Sitemap errors and warnings
If your objective is for Google to crawl every important page on your website, then you need to give those pages the best chance of being discovered.
Ensuring that your XML sitemap is accurate and up to date is key, and you will also need to ensure that the build of the sitemap itself is configured correctly.
If it isn’t, then Googlebot will likely encounter errors, and as a result, will be unable to crawl your referenced pages.
Poor page speed and server response times
Ensuring that your website is accessible has always been best practice, but over recent years, page load speed and site stability have become core considerations for Google when considering the quality of a website.
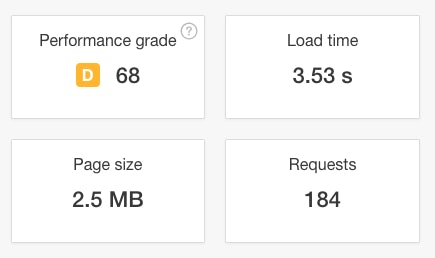
If your site’s pages load slowly, then search engine crawlers will also share that experience. An even worse case scenario is when crawlers are simply unable to connect to the server to crawl URLs in the first place, either because the server is too slow to respond, or because the site is blocking Google. As a result, Google is forced to abandon the request.
Specific errors you might see include:
- Connect timeout
- Connect failed
- Connection refused
- No response
- Truncated response
- Connection reset
- Truncated headers
- Timeout
Ensure you are closely monitoring your server logs, server connectivity errors within the crawl errors report of Search Console and address these accordingly.
Also use the many page speed tools out there such as Google Page Speed Insights, Pingdom Website Speed Test and Web Page Test to identify any opportunities for site speed optimisation.
Soft 404 Errors
Another common occurrence I discover when auditing large scale sites is the existence of “soft 404 errors”. These are essentially pages on the site which no longer exist, yet don’t return the correct 404 header status code.
More often than not, these pages are 302 (temporarily) redirected to a final location URL which then eventually returns a 200 OK status code.
Another common mistake many webmasters make is to display a 404 page, yet not return the appropriate header status code for removed pages.
According to Google, “this is a problem because search engines might spend much of their time crawling and indexing non-existent, often duplicate URLs on your site. As a result, the unique URLs which you are wishing to be discovered may not be crawled as frequently as your crawl coverage is limited due to the time Googlebot will spend crawling non-existent URLs.”
Google recommends that you configure your server to always return either a 404 (not found) or a 410 (gone) response code in response to a request for a non-existent page.
Ensuring your 404 page is a helpful and engaging will help direct users back to your sites valuable pages effectively.
Hard 404 errors
A common misconception is that simply by having 404 errors exist, your sites rankings may suffer. Problems can arise, however, when valuable pages are moved to a new URLs and not redirected correctly using 301 redirects.
There are many instances where there’s solid justification for a page to return a 404 not found status code – namely if the page has been removed as it’s simply no longer required – an occurrence which is certainly much more natural and common on large-scale websites where content frequently updates to reflect database or inventory changes.
404 status codes should always be monitored and essentially you will need to decide if 404’s are worth fixing. I’d suggest prioritising your 404 errors and fix the ones that need to be fixed. Any URLs which don’t require redirecting will simply drop out of Google indexed as they are discovered.
Use Google Analytics to establish if any of the listed URLs receive valuable traffic, and also use a backlink analysis tool such as ahrefs to check if there are any important backlink pointing to the broken URLs – you’ll then be better informed with regards to applying any 301 redirects converse the traffic and link equity passed into to your domain from these URLs.
Duplicate content
Big website = big chance of duplicate content issues.
The nature of the content duplication typically falls into two core categories;
- Issues with the technical build of the site
- The physical content on the pages in question.
In both cases, duplicate content can often be handled by the implementation of a canonicalisation strategy, and you’d be surprised at just how many large, well-established websites are not making use of the canonical tag (rel canonical) to help manage duplicate content errors.
Lack of Canonicalisation
A canonical tag (aka “rel canonical”) is a method of notifying search engine crawlers that a specific URL represents the master copy of a page, and is helpful where there may be confusion for search engines caused by duplicate or similar URLs.
The first major issue which I’ve encountered is that some sites have no canonical tags in place at all.
Each unique page on the site which you are wishing to be indexed should include a self-referencing canonical URL. This will help the search engines to understand that a page is unique if there are similar looking pages across the site.

Of course, you should strive to make each page on this site unique and avoid thin content, but in some instances, it can be difficult when dealing with sites operating on a huge scale.
URL structures, subdomains and protocols
An issue which can often go undetected, yet cause significant duplicate content issues, is URL structures which load both with and without trailing slashes (and sometimes underscores in the URL structure), with each version returning a 200 OK header status code.
If this is happening, then each URL will be treated as unique URL – throw in subdomains and http protocols which are incorrectly configured (www vs non-www & http vs https) and 1 URL can lead to 5 or 6 duplicates in existence.
To avoid duplicate content issues of this nature;
- Ensure that http 301 redirects to https
- Choose either the www or non-www version of your site as your primary version and set this in Google Search Console, as well as ensuring that one 301 redirects to the other.
- Have URLs available to load both with or without trailing slashes, but again ensure one 301 redirects to the other
- Ensure that your canonical URLs reference the single correct URL version
Faceted navigation, filters and internal search
Canonical URLs will help to iron out duplicate content issues when one page is available/accessible within multiple subfolders.
This occurs naturally when a product or service fits into more than one category, but if there’s no canonical (primary URL) set then the search engines will see multiple duplicate pages and be unsure which page to include in their index.
This issue can also occur when large websites use a faceted navigation to allow users to locate products. The image below is taken from a product category page on our client, Hidepark Leather’s website, and as you can see, there are many ways in which users can sort the products within the category, including multiple permutations and therefore the possibility for thousands of unique URLs to be generated. Depending on the scale of the site and the ways in which products can be sorted and viewed, failure to handle faceted navigation can lead to duplication issues on an enormous scale.
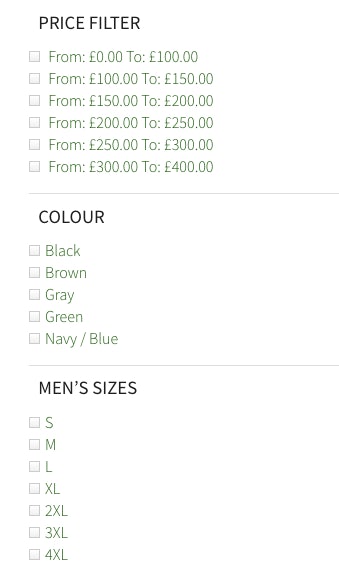
Not only that, but search engines will also spend time crawling the filtered URLs, which is a huge drain on crawl budget. This may lead to less valuable pages being crawled, whilst the pages you’re wanting to be indexed, remain undiscovered.
There are multiple options for handling duplicate content issues of this nature, covered in depth in this post over at Moz, but to summarise, the most common are (and sometimes a combination of);
- Noindex, follow for faceted URLs
- Canonicalisation of faceted URLs back to the primary category page
- Blocking the crawling of these URLs within the robots.txt file to conserve crawl budget
Further crawl waste can be minimised by properly managing your internal site search results pages. Googlebot may try throwing random keywords into your site search – meaning you’ll end up with random indexed pages.
Generally speaking, my own approach to the above issues, although maybe be considered slightly hardline, is to block sorting parameters in the robots.txt by identifying all of the patterns and parameters within the sorted URLs.
If these pages offer no value to search engines, then I really don’t want to waste their time by allowing them to be crawled.

Paginated content
Pagination is common on large scale sites and occurs when content spans over numbers pages as part of categorised series.

At scale, pagination can cause technical SEO issues if not handled correctly; including crawler limitations (as they will likely spend time crawling and trying to index all pages in the series) and duplicate content issues, with meta titles/descriptions, thin/similar content often the main offender.
Once again, there are multiple options for handling paginated content, each with different pros and cons and various levels of complexity regarding implementation.
For optimising crawl efficiency, where possible, I always recommend implementing Rel=”Prev”/”next” to indicate the relationship between component URLs.
This markup provides a strong hint to Google that you would like them to treat these pages as a logical sequence, thus consolidating their linking properties and usually sending searchers to the first page.
Example:
Page 1:
<link rel=”next” href=”www.site.com/page2.html”>
Page 2:
<link rel=”prev” href=”www.site.com/page1.html”>
<link rel=”next” href=”www.site.com/page3.html”>
It is also recommended that each page within the paginated series specifies a self referencing canonical URL element.
In conclusion
The above issues are by no means an exhaustive list. I could produce a tonne of content around the weird and wonderful things I’ve witnessed and had to try and resolve when conducting technical SEO audits and indeed some of the issues above could be expanded upon and covered in greater depth (stay tuned).
That said, these are the most common issues I tend to encounter, particularly when auditing large websites, and hopefully, the advice offered sets you on the right path to fixing any issues you’re experiencing with your websites.


