
What is an SEO site audit?
An SEO audit is an extensive process that all websites would benefit from, forming the foundation of any SEO strategy. An audit can reveal more detail on how a site is crawled, indexed and experienced both by search engines and your audience. Paired with the correct analysis and interpretation, an SEO audit can prove invaluable to a site, identifying ways to improve search engine rankings and traffic through technical SEO improvements that are often simple to implement.
Different checks can reap greater success than others all depending on the issues uncovered by the SEO audit. An audit can include a number of things, from gaining insight on competitors to fixing broken pages and backlinks to reevaluating your target keywords to identifying duplicate content.
However, with hundreds of ranking factors at play, it’s difficult to know where to start. A website audit needs a structured approach; without one, you won’t know what to look at first and what to prioritise.
This blog on how to complete an SEO audit assumes some prior SEO knowledge and aims to provide a structured guide by unpacking a number of on-page ranking factors so that nothing major is overlooked.
Unfortunately, if you want to achieve the best results, you can’t take a one-size-fits-all approach where you pop your domain into a free SEO auditing tool and that’s that. Many of these tools claim to be comprehensive when, in reality, they often fall short. Some simply review your website at page level whilst others are not intuitive enough to unearth the real issues occurring.
A proper SEO audit must be a tailored fit, combining an array of tools and techniques in a holistic approach.
A full technical SEO audit is a long and comprehensive process, usually taking Impression half a day to a few days to complete, depending on the website’s size. However, the guide covered here is a great way to check your site’s current state before any new SEO campaign begins.
1. Preparation
Before starting your on-site audit, there are a few preparatory steps you need to undertake.
1.1 Familiarise Yourself
It may sound obvious, but start your audit by getting familiar with the site in question. Navigate around it to see how it works and fits together. Look from page to page, access as much content as you can, and interact with all the functionality. This will help you later when contextualising the site and prioritising the errors you find.
1.2 Google Analytics & Search Console Access
Ensure you have access to both of these tools prior to starting. Have a look through Google Analytics to determine your site’s key landing pages, the level of organic traffic and the kind of organic engagement the site receives.
Search console is a useful tool for finding out search-related performance, such as keywords the site ranks for and the click-through rates of different pages. It also allows for a whole host of technical insight into your site, which I’ll call upon later when relevant.
(Please note, at the time of writing this post, most of this data is only available via the old Search Console as opposed to the new one. However, I suspect it won’t be long until these old features are ported over.)
1.3 Perform a Website Crawl
This is more of a preparatory step, as crawling a site can take a long time. Your audit will be a lot smoother if you have a fresh crawl ready and waiting for you before you get into it. If you don’t have Screaming Frog SEO Spider, you can download it here. The free version allows for up to 500 URLs to be crawled. You’ll need to consider purchasing a license if you require more URLs than that. The SEO Spider tool is extremely versatile, allowing you to analyse several important aspects of a page.
Other website crawling software we recommend are Sitebulb, DeepCrawl, Botify and Ryte. While all these platforms have certain nuances and USPs that set them apart from one another, the core-requirement of crawling websites for technical SEO analysis remains the same throughout each tool. At Impression, we use a combination of all five, but which you go for will be dependent on your preference and budget.
Once these preparatory steps have been taken, you’re ready to start auditing your site.
2. Crawlability
An important reason to perform an SEO audit is to optimise the crawlability of your site. It costs Google money to crawl the web so it’s in their interest to keep their crawling efficient. By extension, you need to ensure your site is crawl-friendly to ensure Google crawls it regularly. Identify whether the following are in place to ensure an efficient crawl:
2.1 XML Sitemap
You firstly need to establish whether your site has an XML sitemap. Having an XML sitemap helps search engines find content on your site that they otherwise may not have. You can usually check for one by adding /sitemap.xml at the end of your domain, although sometimes the slug can vary with different CMS’s or custom builds.*
If your site does have an XML sitemap, check whether it’s up-to-date and only features indexable URLs. Featuring URLs that are not crawlable or indexable leads to inefficiencies. It’s here where you can also identify whether there is a need for your XML sitemap to include indices, images and/or videos. As a rule of thumb, every individual XML sitemap can hold up to 50,000 URLs and a sitemap index can hold up to 500 XML sitemaps
If your site does not have an XML Sitemap, you can create one using Screaming Frog’s XML Sitemap Generator and upload it into your root directory.
Once all this has been established, another check to perform is whether the XML sitemap has been submitted to Google Search Console and Bing Webmaster Tools. When your sitemap has been picked up you need to check the submitted pages vs indexed pages. This information can be found in Search Console via Crawl > Sitemaps.
(*If your site is on the WordPress platform and uses the Yoast’s WordPress SEO plugin, which many do, your site will automatically have an XML sitemap. This can be found by adding /sitemap_index.xml to the end of your domain.)
2.2 Robots.txt
Similar to XML Sitemaps, the first task here is establishing whether your site has a robots.txt file. If not, it should. Every site needs one. This file is a list of directives that inform search engines where on your site they are allowed and not allowed to crawl. Try locating this file by placing /robots.txt at the end of your domain. If this file is in place, determine whether any folders/paths need adding to it or removing from it.
Robots.txt tells a crawler not to explore a page/area of your site, prohibiting the crawl in those areas altogether, for example:
Disallow: /admin/*
Would stop Google and other search engines from crawling all admin pages. It’s important to note the differentiation between crawling and indexing here. Since we’re inhibiting crawling, it follows that indexing can be prevented also. However, in some circumstances, certain robotted pages can still be indexed, if, for example, they’re linked to from other sites. Optimising your Robots.txt is, therefore, more about managing crawl budget than managing what content is and isn’t indexed.
It’s also good practice to provide a link to the XML sitemap here. If any of these factors apply to your site, highlight them in your audit to action later.
You can read more about robots.txt files here.
2.3 Internal Links
There are many internal linking considerations to look at whilst auditing your site. Firstly, determine whether your site uses absolute URLs instead of relative URLs. In conjunction with this, ensure your preferred URL structure, discussed later in technical duplicate content, is adhered to throughout. This will communicate better to search engines which site version is your prefered configuration and how link equity should flow throughout it.
You also want to have a look at whether your site utilises breadcrumb links. If it doesn’t, decide whether it would be appropriate to do so with the nature of your site. Breadcrumb links have numerous usability benefits as well as SEO benefits, like increased link equity and easier crawlability. Other key internal linking considerations are:
- Avoid linking to non-200 pages, i.e. those that aren’t live
- Ensuring your site is linked to horizontally, as well as vertically
- Avoiding an overly deep site structure
- Ensuring the menu contains all of the top pages
The structure of your site, as well as the internal links, are extremely important, they inform crawlers what your most important pages are impacting how search engines crawl, index and rank your pages. To assess overall internal linking impact, Google uses an internal algorithm called PageRank which “works by counting the number and quality of links to a page to determine a rough estimate of how important the website/webpage is.” Paul Shapiro wrote an interesting article on PageRank if you wish to read more into this.
A simple summary would be, by having the most internal links pointing to a page (typically the home page) this would have a greater PageRank, descending in order to the least important pages with less internal links.
2.4 Response Codes
Using your Screaming Frog site crawl, which will display the response codes next to each URL, to identify any problematic pages. I’ve added a quick overview of the main response codes below.
3xx
The most important here are 301 & 302 codes. A 301 redirect is commonplace on a site and should be implemented as needed. It’s just important to be mindful of redirect loops – whereby there are multiple URLs in a redirect chain. 302 codes, however, are only temporary redirects and do not transfer as much link value. So if we are referring to a permanent change you should ensure that they have a 301 status code.
It’s widely accepted that a 301 redirect will reduce link equity by 15% whereas it’s still debated whether a 302 redirect passes link equity at all. Therefore, while redirects reduce instances of broken links on your site (more on this later), it’s still best practice to update the links referencing these to pages with a 200 status code.
4xx
This group of status codes include 400, 403, 404 and 410. Each one of these should be carefully investigated. A 400 is a bad request and search engines/users can’t access the page, whereas both are actually unauthorised to view 403s. Similarly, servers return a 410 when the page requested has been permanently removed. Finally, 404 status code errors appear for URLs that have been removed or changed location without a redirect.
Although 404s are sometimes inevitable, these types of pages can be problematic for numerous reasons. They can still be found on search engine results pages for sometime after the original URL has been deleted or moved, providing a poor user experience that can impact your user metrics. What’s more, links (both internal and inbound) may be pointing to these URLs, resulting in broken links that impact both user experience and the flow of link equity.
The solution is to use Search Console to determine the amount of 404 errors Google has found and report on these in your audit. As discussed previously, the solution is to implement 301 redirects, redirecting the 404 pages to the nearest equivalent page before updating the link altogether to a 200 page. This would favour your site’s crawlability and restore any lost link equity.
If you want to find out more on this topic we dive deeper into the details here.
5xx
This category of status codes relates to your server and the issues associated with it. These errors can’t be fixed with redirects and instead, should be investigated further with those who host your site.
3. Indexing
Technical Considerations
3.1 Meta Robots Tag
Meta robots tags are a set of directives at page level that inform search engines crawlers how to crawl and index a page, if at all. Although there are many types of meta robots tags, the key ones to look out for are the “noindex” and the “nofollow” attributes. The former is an instruction to not index the page and the latter is an instruction not to follow the links on that page. Use your Screaming Frog site crawl to determine any pages that are inadvertently being blocked. Similarly, check to see if any pages could do with these meta robots tags being put in place.
3.2 Canonical URL
Canonical URLs are a useful SEO tool for resolving potential duplicate content issues. Ideally, there should be canonicals in place sitewide; every page’s rel=canonical can be self-referencing unless there is a risk of duplication. For example:
- https://www.example.com/product1/
- https://www.example.com/product1_?=querystring/
The duplicate page could have a rel=canonical set as the first URL. This is, of course, an alternative solution to a 301 redirect.
Screaming Frog lists out the canonical for each URL making it easier to find out if a canonical URL is implemented for a page.
3.3 Hreflang
The hreflang attribute is another useful tool in the SEO arsenal and essential for any site that is international or multilingual. Serving multiple countries and languages is great for the UX of a site, but you want to ensure that search engines understand which pages to serve to users who could be searching in different languages or locations. An example hreflang attribute for the UK and US version of a page would be:
- <link rel=”alternate” href=”http://example.com” hreflang=”en-uk” />
- <link rel=”alternate” href=”http://example.com/us/” hreflang=”en-us” />
It’s important to note that although the above hreflang example indicates to Google which page to serve to the UK and US audience respectively, it does not combat duplicate content issues if the content is exactly the same on both pages. However, it’s a step in the right direction and starts to alleviate duplicate content.
Further, canonical URLs must not reference a page from a different regional variant of the site, otherwise, a search engine won’t know which to use as a reference.
3.4 URL Structure
Knowing your business and the products or services that are on show, does the URL structure make sense? For instance, for an electronics eCommerce client, where does the Hotpoint WMAQF721G product page sit?
It’s a Washing Machine – that’s what the WM at the beginning of WMAQF721G stands for – so ideally it should nest under /washing-machine/ to give /washing-machine/wmaqf721g. Depending on the site’s organisation, you may even want to consider including the brand name or something similar to a sub-folder between the category and product.
Some clients sites and product codes may not be as simple as this though, so you need to check if every page is under an appropriate category within a structured hierarchy. Good URLs are accurate descriptions of the page, including target keywords.
With regards to site structure it’s important that the site’s top pages are close to the homepage: easy to find and not several clicks deep. Nesting the page too deeply will negatively impact traffic to the said page. There is a great blog article on website architecture here for further information.
3.5 Structured Data
As part of your SEO audit, it is worth testing any structured data that the site may contain and ensuring that it is properly implemented. Correctly implemented structured data, referred to as a ‘schema’ or ‘microdata,’ can increase visibility in the SERPs and lead to improved click-through rate.
Through a collaboration between major search engines that allows structured data to be recognised, the markup language helps search engine bots better understand your site’s content and improve the way that your search result are displayed by forming appropriate rich snippets.
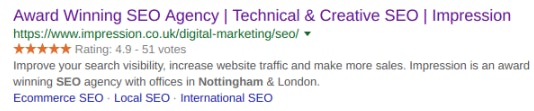
The above example shown in the SERPs has 4 types of structured data implemented: Orginization, LocalBusiness, Website and Breadcrumb. Impression has written a blog going into the implementation of several common schema here. Content that is set to benefit from such structured data include reviews, product pages and events.
You can audit the structured data on your site using Search Console, which will break down all the items with errors To get an even more in-depth analysis of your site, we suggest using Google’s Structured Data Testing Tool. Simply paste the URL into the tool in New Test – Fetch URL – Run Test.
3.6 HTTPS
Websites should all really be HTTPS by now or, at least, about to migrate to HTTPS. The security benefits and signals to users are explained in more detail here. Other benefits include improved site speed and the positive part it plays as a ranking factor.
When auditing an HTTPS site, look out for any HTTP pages. First, check to see if these are duplicates of the HTTPS domain. If they are, 301 redirect the HTTP variant to the secure protocol. If not, either remove the page or duplicate it on HTTPS. A recrawl on Screaming Frog will then confirm if you have been successful.
3.7 Technical Content Duplication
This is not referring to duplicate content from plagiarised copy, but duplicate content that’s due to incorrect technical configuration on your site, like the abovementioned HTTPS & HTTP variants.
Your site should have a preferred URL destination, to which all other variants of the URL 301 redirect. Examples of these variants of your root domain include non-www and trailing slash versions of your URLs (and vice versa). Check whether your site has these redirects in place by manually seeing whether or not the variants redirect to your preferred URL in your browser.
Technical duplicate content can also occur with pagination or any type of filtering functionality that may be present on your site. You’re essentially looking for instances where your URLs are changing but the same or very similar content is being served. For instance, a common technical duplicate content issue amongst eCommerce sites is where the same products can be found via different category routes:
- https://www.example.com/product-1
- https://www.example.com/category-a/product-1
- https://www.example.com/category-b/product-1
This is an example of technical duplicate content as the same product can be found on 3 URLs. In this instance, the simplest solution your audit can suggest is to implement canonical tags, where all versions of the URLs are pointing to a preferred URL.
Content Considerations
3.8 URLs
The key with URLs is that they need to make sense semantically, i.e. the user is meant to be able to suss out exactly what the page is about simply by reading the URL. Start by looking at your Screaming Frog site crawl and analysing the URLs in the ‘Address’ column. You need to determine whether they’re clean and keyword optimised. Cross-reference them with your keyword research to determine this. Google also recommends that hyphens are used as separators between words instead of underscores or any other characters. The lengths need to be short and concise – under 115 characters if possible – although this may be difficult to achieve depending on the topic of the page.
Solving incorrectly formatted URLs requires some technical know-how and caution. Simply changing them will result in several 404 error pages being created from the old URLs. Ensure that yourself or your developer knows how to 301 redirect the old URLs to your new, correctly-formatted URLs.
3.9 Title Tags
Each page on your site needs to have a uniquely written title tag that is approximately 50-60 characters in length (depending on character pixels). Common issues are title tags that are missing completely, duplicated title tags and title tags with an incorrect character length. To determine whether your site has any of these issues, the panel on the right-hand side of the Screaming Frog window categorises all metadata to show where issues are.
Like URLs, title tags need to be summative of what the page is about. Title tags are also a substantial on-page ranking factor, meaning they need to be keyword targeted for optimum performance. Using Screaming Frog, determine whether your title tags are keyword optimised by cross-referencing them again with your keyword research.
3.10 Meta Descriptions
With meta descriptions, you’re fundamentally looking for the same issues as you are with title tags, i.e. missing or duplicate meta descriptions. The character allowance for meta descriptions is 150-160 characters. This limit increased briefly to 320 in December 2017 but has now reverted. If you exceed the limit, the description will be truncated in the SERPs. Again, you can find whether your site has any of these errors by using Screaming Frog crawl.
A new feature with Screaming Frog’s version 10.7 is the ‘metadata optimiser.’ this allows for each URL to be selected and the title and description edited to check for the correct length and duplication. Once completed, these can be exported to be implemented on site, making this often lengthy process quicker.
Although meta descriptions are not strictly a ranking factor, keywords placed here will be highlighted bold in results pages if they correspond with a user’s search query. It’s therefore worth examining whether your meta descriptions are keyword optimised. It’s also helpful if your meta descriptions are persuasive, not self-promotional and incorporate calls-to-action. This will all lend a hand to encouraging a higher click-through rate to your site.
3.11 Header Tags
A Screaming Frog site crawl will let you uncover exactly what is going on with your header tags. With h1 tags, you’re ideally looking for a unique, sufficiently keyword optimised tag on each page. This is another element a search engine will look at to try and determine the relevancy and context of a webpage. Subheading tags – h2s, h3s etc. – should be used to wrap any subsequent subheadings.
All remaining tags are to be used if the content allows for it. You’re looking for a structured hierarchy here, with each subsequent tag nested under the preceding tag. A common issue to look out for is whether headers are even wrapped in a tag and whether a hierarchy is followed.
3.12 Body Content
The on-page copy is a massive consideration when auditing a website from an SEO perspective.
A good starting point here is to analyse your Screaming Frog site crawl to determine the word count of each page. Although many external tools and resources will state that a minimum of 300 words is required for every page, this isn’t entirely true all of the time. It’s simply important for your key landing pages to have a healthy amount of rich, sufficiently keyword optimised copy. You can use Google Analytics to determine exactly what your key landing pages are (or, conversely, the landing pages that aren’t performing but should be) to determine whether any copy needs amending or adding to.
Duplicate content is arguably the biggest consideration with body copy but, annoyingly, the trickiest one to audit. It’s not a case of having duplicate content or not, it’s a case of exactly how much duplicate content is at play. If your site is small enough, you could search Google with the “ ” search operator to determine exactly which snippets of content are duplicated.
Alternatively, just analyse your key landing pages with this method, especially if your site is of a larger size. A little trick is to think about exactly which pages are likely to host duplicate content. For example, it’s common for snippets from your home or about page to be featured elsewhere on the web. Similarly, if your site features product pages that are also sold elsewhere, check whether the description has been pulled from the manufacturer’s website.
It’s worth remembering at this point about previously discussed methods to address duplicate content with meta robots tags, canonicals, robots.txt and 301 redirects, where changing or creating new content isn’t a feasible option.
3.13 Image Alt Text
Image alt text is used to provide a description of an image on a page should it not render for the user. This can often be overlooked but is valuable for SEO: image alt text contributes to how search engines identify the content of an image. This helps them to understand the topic of the whole page and to correctly rank the asset in image searches. In order for an image to be served in a featured snippet, for instance, it would have to have relevant image alt text for the users query.
4. Performace
4.1 Page & Site Speed
We know that page speed is one of the most important technical considerations. It has long been established as one of many Google ranking factors. But a mobile page speed update coming into effect early this year has taken the importance a step further.
A site should be optimised for speed for the usability benefits as much as ranking factors, with some experts suggesting a load time of fewer than 2 seconds is essential. A slow loading site can provide a frustrating user experience, affecting your usage metrics, and has even been shown to negatively affect conversion rates.
Most tools out there will analyse your site’s speed at a page level, which is normally a good indication of how your site is faring overall. Use Google PageSpeed Insights, Google’s own tool, help you identify your site speed in relation to others through their grading system.
Another good free tool is Pingdom, which also give relative scores and offers granular insight into areas that you should fix and consider fixing.
4.2 Mobile Optimisation
Google is now rolling out it’s mobile-first index for sites across the UK. You may have already had an email explaining how Googlebot will now use the mobile version of your site for indexing and ranking to better help users find what they’re looking for. Mobile optimisation could justify its own audit.
However, for the purposes of analysing your site holistically alongside other SEO factors, there are a few fundamental checks you can perform quickly to determine how your site copes with mobile.
To start with, check if your site is even mobile optimised. Ideally, you’re looking for a responsive design. Am I Responsive? is a cool interactive tool you can use to figure this out. Alternatively, just load your site on your smartphone to see how it renders.
Your next port of call is to head over to Search Console’s ‘Mobile Usability’ section to see whether Google is detecting any issues. This feature will look at 4 components: the touch elements being too close together, the content not being sized to the viewport correctly, the viewport not being configured and the font size being too small. Take note of which pages Google identifies as having these issues and highlight them in your audit to work through later.
It’s also worth examing the difference in internal and inbound links between your mobile and desktop site. Ideally, these should be comparable so your PageRank is not affected in light of mobile-first indexing.
Finally, it is worth evaluating the usability of your mobile site. Browse the site on your smartphone and see whether there are issues that may prevent your users from converting. You need to watch out for the little things like the dialler app not opening correctly or enquiry forms not being sized correctly. Mobile traffic continues to grow exponentially for many sectors and industries, so it’s important to take into account UX for mobile as well as desktop.
5. Off-Page Optimisation
Off-page optimisation is defined as improving your brand’s online and offline presence through content, relationships and links to create an optimal experience for users and search engine crawlers.
For the purpose of an SEO audit, we would focus off-page attentions on a site’s backlink profile. The necessity of links in modern SEO is well known and documented. In order to grow your website’s authority and rankings, you need new links to your site.
But while links are essential, not all are equal. To assess the quality a site’s links we use Kerboo but there are other link auditing sites out there, including Ahrefs. Kerboo software enables you to see the existing backlink profile for your site which will help you to:
- Identify good and bad quality links that will be either positively or negatively impact a site
- Spot any suspicious, bad links that can be investigated further and disavowed where appropriate
- Weigh up the link risk vs link value of your backlink profile and each respective backlink
- See broken links and missed opportunities
- Check for anchor text optimisation or over-optimisation
- Analyse your current disavow file (if you have one in place) and question how appropriate it is to reavow some links
Summary
We’ve delved into the three core areas of SEO here from crawling, indexing to authority considerations. All three of these areas are fundamental to how a search engine operates and are, therefore, fundamental to cover during a technical SEO audit.
Altogether, you should now have a substantial list of issues that need correcting across your site. Once even a fraction of these are actioned, the site’s performance will undoubtedly improve as it works to better please search engine crawlers and build a more fluid user experience. This all builds trust in your website and, ultimately, your business.
However, no matter how much detail we go into there’s always going to be issues unique to your site. It’s important to step in the shoes of your user and be thorough. Some issues may seem trivial – like a missing favicon, for instance – but if you’ve noticed it, it’s likely others will too.
If your site requires an SEO audit and you don’t have the resources or time in place to conduct one, feel free to get in touch with Impression.


